
Despite achieving technical benchmarks comparable to OpenAI’s other powerful AI models, the initial response from the broader AI developer and user community has been mixed. If this release were a film being rated on Rotten Tomatoes, it would likely result in a near 50% split.
Some background: OpenAI has introduced two new text-only language models (excluding image capabilities) under the open source Apache 2.0 license—the first such release since 2019.
For the last 2.7 years, the era of ChatGPT has been dominated by proprietary models under OpenAI’s control, accessible through paid tiers or with restrictions, lacking full customizability and offline use.
With the release of the gpt-oss models, things have changed. One is designed for a single Nvidia H100 GPU suitable for enterprise data centers, while a smaller model can run on a typical consumer PC.
Since their release, users have taken time to independently test these models on various benchmarks.
Feedback ranges from optimistic excitement about the potential of these free models to dissatisfaction with perceived limitations, especially when compared to powerful open source models from Chinese startups.
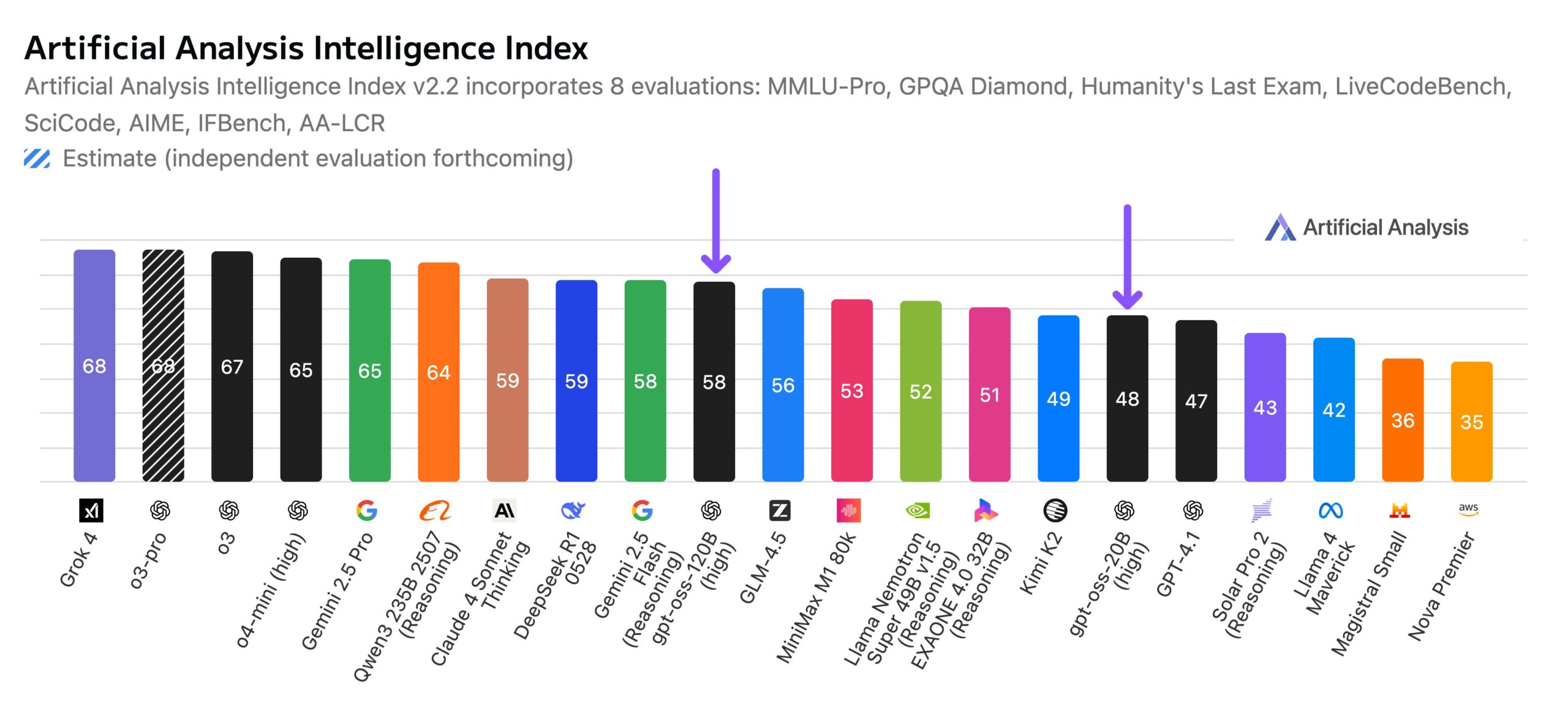
High benchmarks, but still behind Chinese open source leaders
The gpt-oss models have intelligence benchmarks that surpass most American open-source offerings. According to AI benchmarking firm Artificial Analysis, gpt-oss-120B is the most intelligent American open weights model, though it lags behind Chinese models like DeepSeek R1 and Qwen3 235B.
The skepticism is echoed by experts who doubt any significant new use cases will come from these models. Open source researchers predict Chinese models will soon surpass it.
Bench-maxxing on math and coding at the expense of writing?
Critics point out the gpt-oss models’ narrow range of usefulness. An AI influencer noted their proficiency in math and coding but criticized their creative writing capabilities. In writing tests, the models would insert equations improperly, indicating an overemphasis on benchmark performance.
It’s suggested that the training relied more on synthetic data to avoid legal issues with copyrighted content, impacting its ability to generalize beyond trained tasks.
Others speculate that the model was primarily trained with synthetic data to bypass safety concerns, resulting in subpar quality.
Concerning third-party benchmark results
Evaluation on third-party benchmarks has revealed troubling results. SpeechMap indicates low scores in generating restricted, biased, or politically sensitive content. In multilingual reasoning, the model scores below many competitors. Users report an odd resistance to criticizing certain countries, raising questions of bias.
Other experts applaud the release
Not all feedback is negative. Some experts laud the models’ efficiency and performance, particularly in reasoning and STEM benchmarks, and find the release a significant positive move for U.S. open source AI.
Caution remains about whether OpenAI will continue to update these models, as competition is quick to evolve.
Overall, reactions are mixed. OpenAI’s gpt-oss models present important progress in licensing and availability. However, the impact of these models in practical applications remains to be seen. The success of the release depends on future developments and enhancements.