
Small AI models are gaining traction. Following the release of an AI vision model small enough for smartwatches by MIT spinoff Liquid AI and another suitable for smartphones by Google, Nvidia introduces its own small language model, Nemotron-Nano-9B-V2. This model, with its 9 billion parameters, outperforms its class on certain benchmarks and includes a feature for enabling or disabling AI “reasoning” before generating answers. Although larger than some multimillion parameter models, it is a reduction from 12 billion parameters and can operate on a single Nvidia A10 GPU. Nvidia’s Oleksii Kuchiaev explained that the reduction aligns it with the A10 GPU, making it faster and capable of handling larger batch sizes.
In the AI space, models frequently exceed 70 billion parameters. Despite this, the smaller Nemotron offers notable performance across multiple languages, including English, German, Spanish, French, Italian, Japanese, Korean, Portuguese, Russian, and Chinese, and is adept at instruction following and code generation.
Nemotron-Nano-9B-V2 and its training datasets are accessible on Hugging Face and Nvidia’s model catalog. It combines Transformer and Mamba architectures to manage long sequences with a mix of attention layers and state space models, offering linear scaling and reduced memory and compute costs. This approach also appears in models from labs like Ai2, emphasizing efficiency and cost management.
The model, designed for text-based chat and reasoning, defaultly generates a reasoning trace, but this can be adjusted using control tokens. It also includes a feature to manage “thinking budgets,” controlling token usage for internal reasoning to balance accuracy and latency, vital for customer support and autonomous agents.
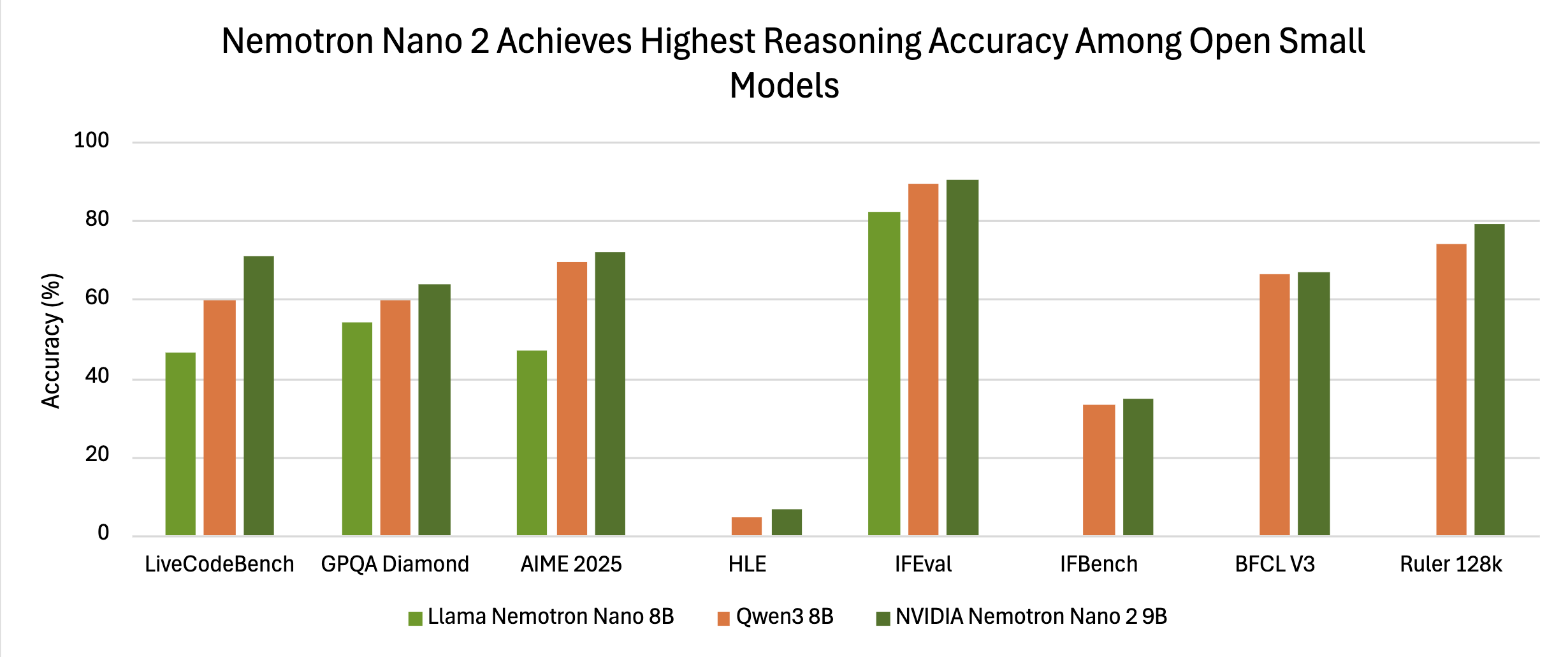
Benchmark tests show Nemotron’s competitive accuracy. In “reasoning on” mode, it scored 72.1% on AIME25, 97.8% on MATH500, 64.0% on GPQA, and 71.1% on LiveCodeBench. Its accuracy surpasses other small-scale models like Qwen3-8B, with Nvidia highlighting the effectiveness of controlled reasoning token budgets to optimize performance in production settings.
Training relied on various data sources, including synthetic reasoning traces to improve complex benchmark performance. Released under the Nvidia Open Model License, Nemotron-9B-V2 is commercially viable from launch, with no usage thresholds or fees. Developers can freely build and share derivative models, abiding by compliance and ethical use provisions.
Nvidia’s strategic positioning of Nemotron-Nano-9B-V2 highlights deployment efficiency at smaller scales with flexible accuracy management. Its availability on Hugging Face and Nvidia’s catalog aims to facilitate accessibility for development and integration, focusing on hybrid architectures and innovative training to balance cost and latency while maintaining accuracy.