
Liquid AI has launched LFM2-VL, an advanced vision-language foundation model for seamless deployment across diverse hardware, including smartphones, laptops, wearables, and embedded systems. These models ensure low-latency performance, high accuracy, and adaptability for practical applications.
Building on the LFM2 architecture, known for its “weights” or model settings generated dynamically for each input (Utilizing the Linear Input-Varying (LIV) system), LFM2-VL supports multimodal processing, handling text and image inputs at various resolutions. Liquid AI states the models provide up to twice the GPU inference speed compared to similar models, while sustaining high benchmark performance.
“Efficiency is our product,” noted Liquid AI co-founder and CEO Ramin Hasani in a post on X introducing the new model family. The lineup features two versions: LFM2-VL-450M, a hyper-efficient model with under half a billion parameters for resource-limited settings, and LFM2-VL-1.6B, a more powerful yet lightweight model for single-GPU and device-based use.
Each model processes images in native resolutions up to 512×512 pixels, eliminating distortion or excessive upscaling. Larger images are managed using non-overlapping patches with an additional thumbnail for context, allowing the model to capture detailed and broader scenes simultaneously.
Liquid AI originates from MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL), with a mission to develop AI architectures surpassing the prevalent transformer model. Its flagship Liquid Foundation Models (LFMs) employ principles from dynamical systems, signal processing, and numerical linear algebra, creating versatile AI models for text, video, audio, time series, and other sequential data.
Recently, Liquid AI introduced the Liquid Edge AI Platform (LEAP), a cross-platform SDK facilitating developers in running small language models on mobile and embedded devices. LEAP supports various operating systems, integrating both Liquid’s models and other open-source SLMs, alongside a model library under 300MB—ideal for modern phones with limited RAM.
The LFM2-VL architecture uses a modular structure, incorporating a language model backbone, a SigLIP2 NaFlex vision encoder, and a multimodal projector, which includes a two-layer MLP connector with pixel unshuffle to reduce image tokens and enhance efficiency. Users can balance speed and quality by adjusting image tokens or patch parameters, with training involving roughly 100 billion multimodal tokens sourced from open datasets and in-house synthetic data.
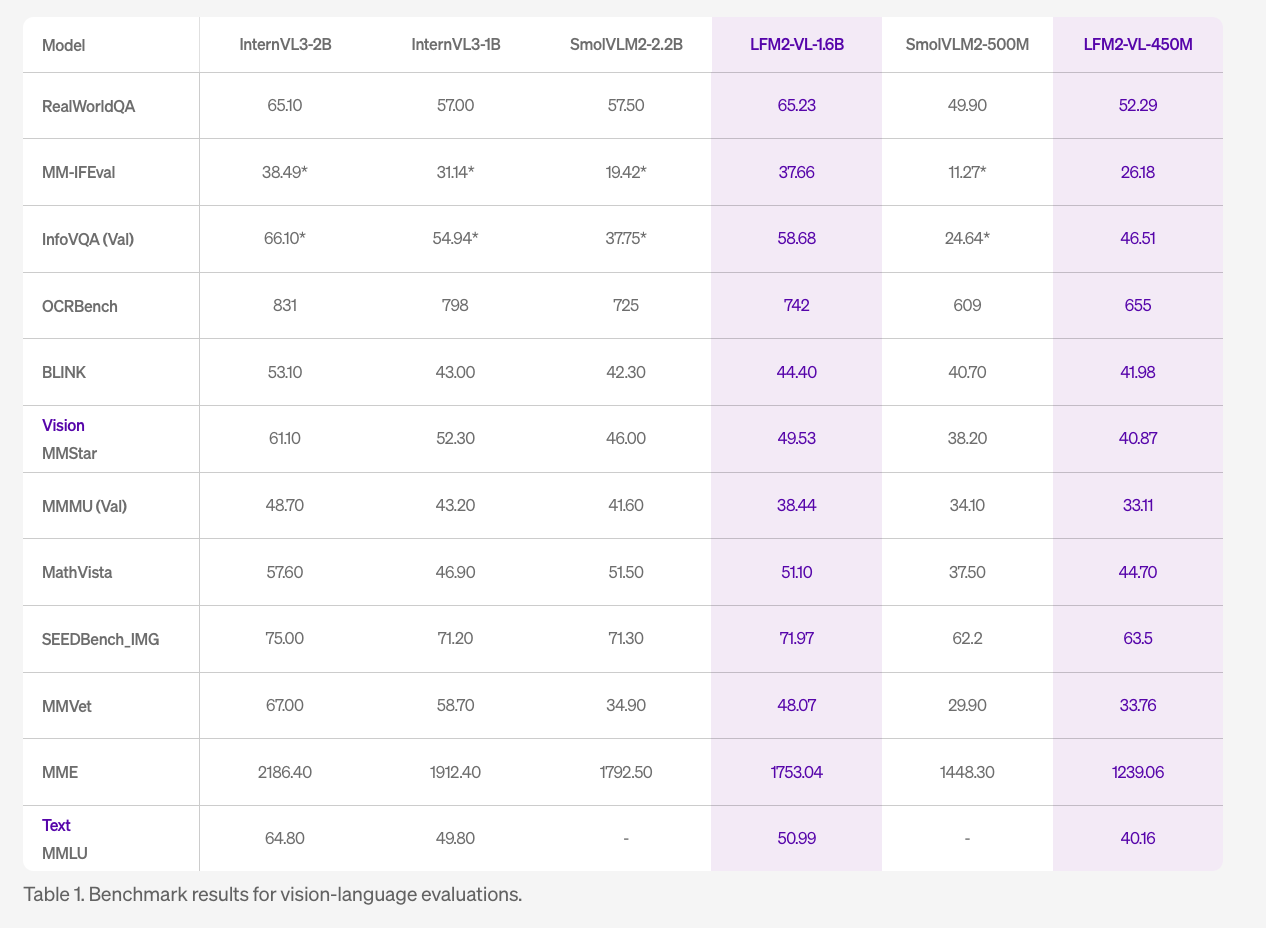
LFM2-VL provides strong benchmark results across various evaluations, excelling in categories like RealWorldQA (65.23), InfoVQA (58.68), and OCRBench (742), while maintaining robust performance in multimodal reasoning tasks. It stands out for GPU processing speed when tested with standard workloads.
Available on Hugging Face with example fine-tuning code in Colab, the models are released under a custom LFM1.0 license, based on Apache 2.0 principles, but the full details remain unpublished. Liquid AI indicates that commercial use will be conditional, with different terms for companies based on revenue.
With LFM2-VL, Liquid AI seeks to make powerful multimodal AI accessible for on-device and resource-limited deployments without compromising performance.