
Researchers from the University of California, Berkeley, Stanford University, and Databricks have introduced a new AI optimization method called GEPA that significantly surpasses traditional reinforcement learning (RL) techniques for adapting large language models (LLMs) to specialized tasks.
GEPA substitutes the typical trial-and-error learning paradigm, guided by simple numerical scores, with the use of an LLM’s language understanding to evaluate its performance, diagnose errors, and refine its instructions iteratively. It proves more accurate and efficient than traditional methods, achieving superior results with up to 35 times fewer trial runs.
For businesses developing complex AI agents and workflows, GEPA means faster development cycles, notably reduced computational costs, and more reliable applications.
Most enterprise AI applications are not just a single LLM call. They are often elaborate “compound AI systems,” complex workflows chaining multiple LLM modules, external tools, and custom logic to execute sophisticated tasks, such as multi-step research and data analysis.
A prevalent optimization method is using RL techniques like Group Relative Policy Optimization (GRPO). This method treats the system as a black box, providing simple scalar rewards, like a score, to gradually adjust the model’s parameters. However, RL suffers from sample inefficiency, often requiring extensive trial runs, which is slow and costly for many real-world applications involving powerful models or expensive tool calls.
Lakshya A Agrawal, a co-author of the paper and doctoral student at UC Berkeley, explains that RL’s cost and complexity present a significant barrier for companies. For many, prompt engineering by hand is more practical. GEPA is designed to optimize systems using top-tier models that cannot be fine-tuned, improving performance without needing to manage GPU clusters.
The challenge is: “How can we maximize learning signals from each costly rollout to adapt complex, modular AI systems effectively in low-data or budget-constrained situations?”
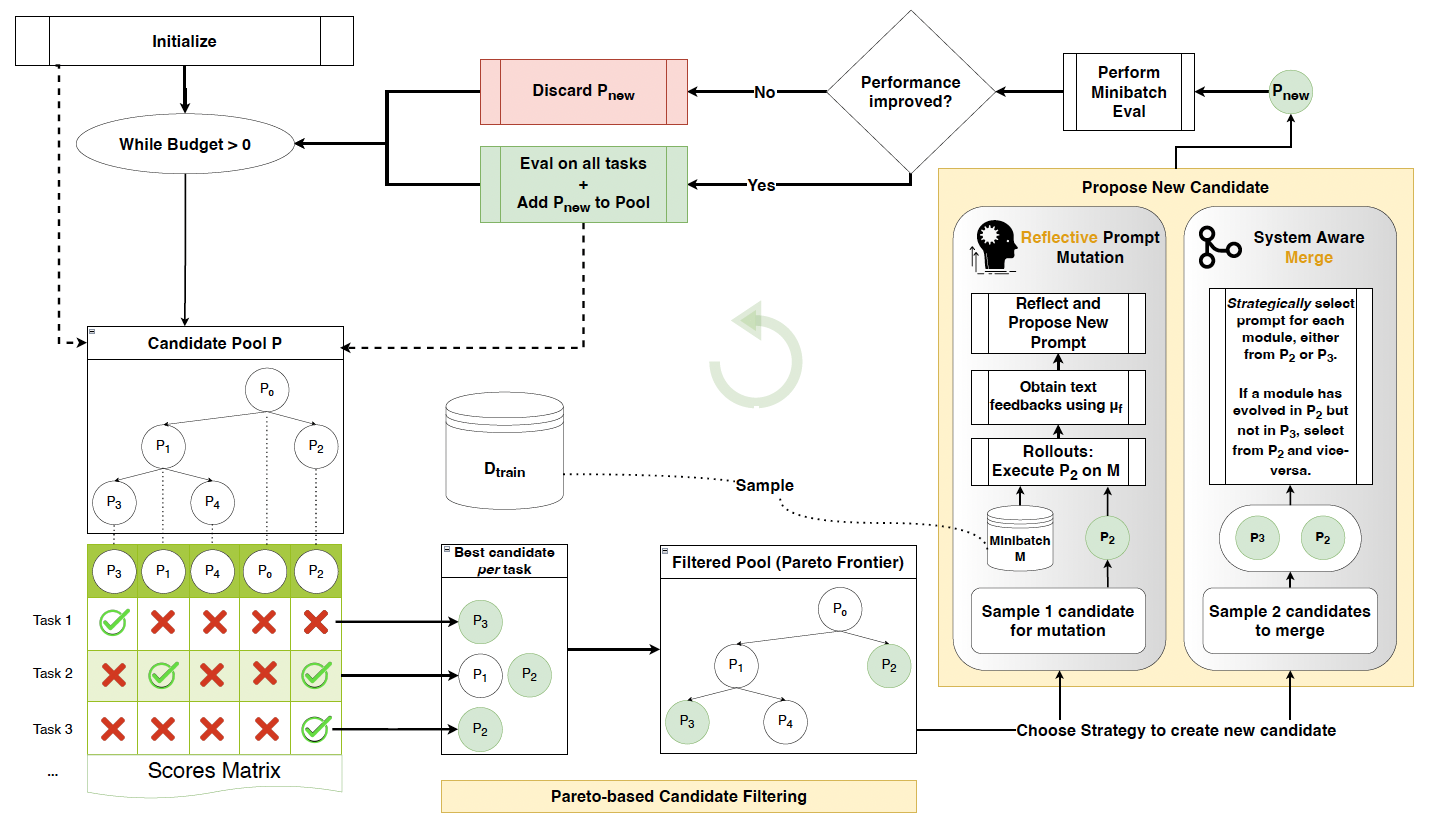
GEPA (Genetic-Pareto) tackles this challenge with a prompt optimizer using rich, natural language feedback. It translates AI system executions into serialized text that an LLM can interpret. GEPA relies on three core principles:
1. Genetic prompt evolution: GEPA treats a pool of prompts as a gene pool, iteratively mutating them to create improved versions.
2. Reflection with natural language feedback: After several rollouts, GEPA provides an LLM with a full execution trace and outcome, allowing it to analyze the problem and refine the prompt.
3. Pareto-based selection promotes exploration, sampling from a diverse set of strategies to avoid suboptimal solutions.
This feedback engineering focuses on exposing rich, textual details that systems produce but often discard, rather than reducing them to a single numerical reward.
Examples include listing documents retrieved correctly and missed rather than calculating final scores.
Researchers tested GEPA on diverse tasks, such as multi-hop question answering (HotpotQA) and privacy-preserving queries (PUPA), using both open-source and proprietary models. GEPA outperformed RL-based GRPO, achieving up to 19% higher scores with up to 35 times fewer rollouts. Optimizing a QA system with GEPA took about 3 hours versus GRPO’s 24 hours, reducing development time significantly while achieving better performance and costing far less in GPU time.
GEPA-optimized systems show better reliability when encountering new data, thanks to learning from rich feedback. This means less brittle and more adaptable AI applications for enterprises.
GEPA’s prompts are much shorter than those from other optimizers, reducing latency and costs for API-based models, resulting in faster and cheaper production.
Additionally, GEPA promises success as an “inference-time” search strategy, transforming AI from a single-answer provider to an iterative problem solver. Agrawal describes GEPA’s integration into company pipelines as an automated optimization process that could surpass expert hand-tuning.
Ultimately, GEPA aims to make AI optimization more accessible, allowing end-users with domain expertise to engage in building high-performing systems without necessarily mastering complex RL specifics.