
The emergence of Deep Research features and AI-driven analysis has led to more models and services designed to simplify document processing for businesses.
Cohere, a Canadian AI company, is leveraging its models, including a newly launched visual model, to advocate for optimizing Deep Research features for enterprise applications.
The company introduced Command A Vision, a visual model focused on enterprise use, built on its Command A model. This 112 billion parameter model aims to extract valuable insights from visual data, making data-driven decisions through document OCR and image analysis.
“Whether deciphering complex diagrams in product manuals or assessing photos for risk, Command A Vision tackles challenging enterprise vision tasks,” the company stated in a blog post.
Command A Vision can read and analyze images commonly needed by enterprises, including graphs, charts, diagrams, scanned documents, and PDFs.
Released on Hugging Face, Command A Vision, based on Command A’s architecture, requires two or fewer GPUs and retains the text model’s capabilities to read text on images, supporting at least 23 languages. Unlike other models, Command A Vision is cost-effective and optimized for enterprise retrieval use cases.
Cohere used a Llava architecture to develop its Command A models, including the visual model, converting visual elements into soft vision tokens and feeding them into a dense 111B parameter textual LLM. This allows a single image to consume up to 3,328 tokens.
The visual model underwent three training stages: vision-language alignment, SFT, and RLHF. “This enables mapping image encoder features to the language model embedding space,” the company explained.
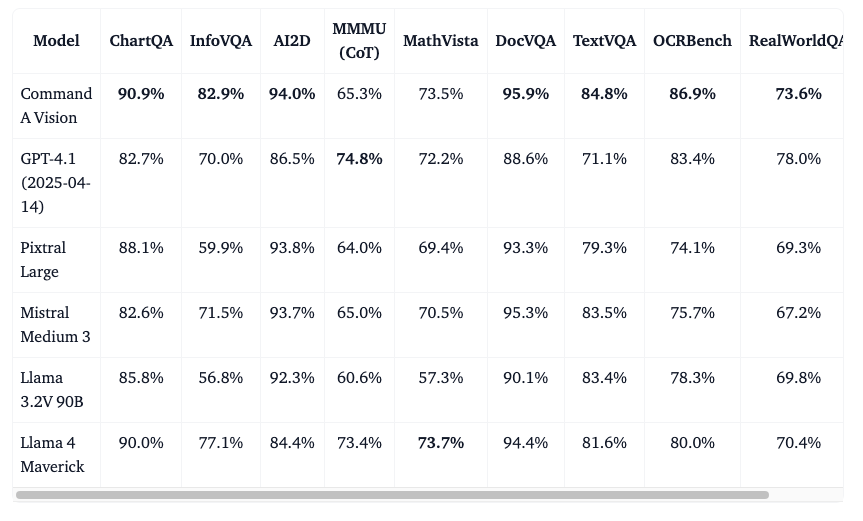
In benchmark tests, Command A Vision outperformed models with similar visual capabilities, surpassing OpenAI’s GPT 4.1, Meta’s Llama 4 Maverick, and Mistral’s models in nine benchmark tests, achieving an average score of 83.1%.
Given the rise of Deep Research, the demand for models capable of processing unstructured data like charts and PDFs has increased. Cohere aims to attract enterprises shifting from proprietary models by offering Command A Vision with open weights. Developer interest has been noted.
Some developers expressed satisfaction with the model’s accuracy in extracting handwritten notes and appreciated its understanding of non-standard visuals.
Cohere invites insights on business use cases with VB Daily, offering updates on company activities with generative AI. Read the Privacy Policy for more information.