
The adoption of interoperability standards, like the Model Context Protocol (MCP), can offer enterprises deeper insights into how agents and models operate beyond their boundaries. However, many benchmarks do not encapsulate real-world interactions with MCP. Salesforce AI Research has introduced an open-source benchmark called MCP-Universe, designed to evaluate LLMs as they engage with MCP servers in practical settings, asserting it will provide a clearer understanding of real-time, real-life model interactions with tools enterprises use. Initial tests show models like OpenAI’s newly released GPT-5 are strong but not exemplary in real-world scenarios.
Current benchmarks largely assess isolated LLM performance aspects, such as instruction following or math reasoning, without fully evaluating how models interact with real-world MCP servers across diverse environments, Salesforce stated in a paper. MCP-Universe measures model performance through tool usage, multi-turn tool calls, extensive context windows, and vast tool spaces, grounded on real MCP servers with genuine data sources and settings.
Salesforce’s Junnan Li mentioned that many models face constraints in enterprise-grade tasks. Two significant challenges are: long context difficulty, where models might lose track or struggle with reasoning when given lengthy or complex inputs, and unfamiliar tool difficulty, where models can’t adapt to unfamiliar tools or systems like humans can. It’s crucial to avoid DIY approaches with a single model for agents, and instead, utilize a platform that integrates data context, enhanced reasoning, and trust safeguards to fully support enterprise AI.
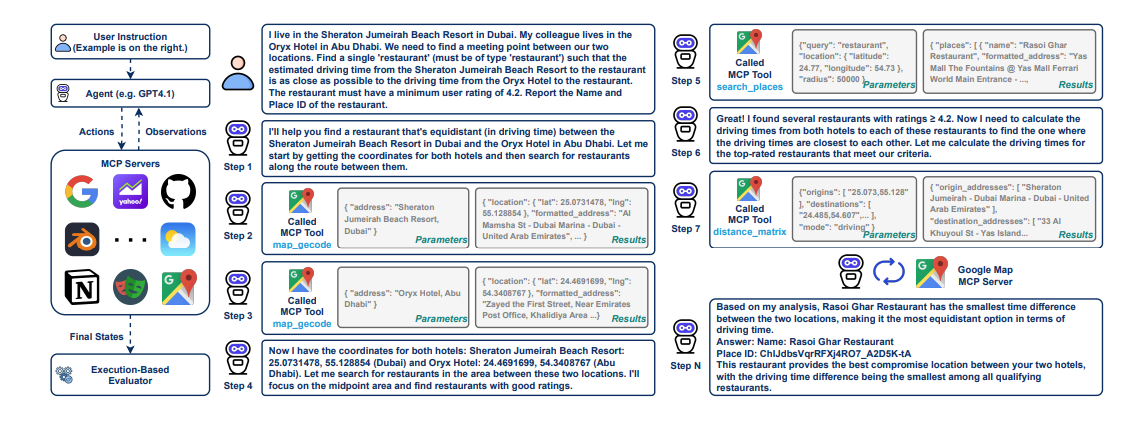
MCP-Universe joins other MCP-based benchmarks, such as MCP-Radar from the University of Massachusetts Amherst and Xi’an Jiaotong University, and MCPWorld from Beijing University of Posts and Telecommunications. It also builds on MCPEvals, a benchmark Salesforce released in July, which primarily targets agents. Li noted the main difference is that MCPEvals uses synthetic tasks, whereas MCP-Universe evaluates how effectively models perform enterprise-like activities. The benchmark covers six core enterprise domains: location navigation, repository management, financial analysis, 3D design, browser automation, and web search, accessing 11 MCP servers for 231 tasks.
Salesforce committed to designing new MCP tasks that resonate with real-world use cases. For each domain, researchers created four to five tasks they believed LLMs could accomplish. Models might, for instance, be tasked with route planning, identifying optimal stops, and locating destinations. Models are assessed based on how they execute these assignments, using an execution-based evaluation method instead of the common LLM-as-a-judge system, which is unsuitable for this scenario due to tasks requiring real-time data while LLM knowledge is static.
Salesforce tested numerous proprietary and open-source models on MCP-Universe, noting GPT-5 had the best success rate overall, excelled in financial analysis tasks, and Grok-4 led browser automation, with Claude-4.0 Sonnet ranking third. Among open-source models, GLM-4.5 performed best. However, MCP-Universe revealed models struggle significantly with long contexts, notably for location navigation, browser automation, and financial analysis, and their efficiency decreases markedly when faced with unknown tools.
These results highlight that current forefront LLMs still struggle with reliably executing tasks across varied real-world MCP engagements. Thus, MCP-Universe provides a critical, challenging testbed for assessing LLM aptitude in areas not well-served by existing benchmarks. Li hopes enterprises will use MCP-Universe to thoroughly understand where agents and models falter in their activities to enhance either their frameworks or MCP tool implementations.